
In this project, I aimed to answer a pertinent subquestion related to my overall thesis project. Overall, I seek to reconstruct the history of Mahmadou Lamine Dramé, a nineteenth-century Islamic leader from what is now eastern Senegal. My specific research question was, simply put:
How did French officers talk about Mahmadou Lamine Dramé and his nascent attempt at state-building, and how can we compare this written narrative to the one that appears across the letters Mahmadou sent to French colonial administrators?
This query matters to my work because it allows me to outline an essential historical misinterpretation of Mahmadou’s motives vis-à-vis the French colonial state—one that is described in the texts and has had wide ramifications across later historiography. This is a type of question which, I felt, was best approached by paying close attention to semantics and word use in texts.
As a student in a digital humanities course at the Aga Khan University, I was expected to use digital methods to explore a research question. A plethora of machine-learning tools have been developed that are capable of digitally performing semantic analysis at massive scales. These were used experimentally in the series of processes, or pipeline, at the center of my project. My primary goal was to develop a usable text-mining methodology in order to access meanings and trends across a series of texts. Topic modelling and clustering were key here: these are two mathematically complex machine-learning methods developed precisely to discover such meanings and trends in large textual corpora. These methods fall under the umbrella of unsupervised learning, meaning the analysis of data by a computing model operating autonomously, searching for patterns and trends that might take a human researcher weeks or longer to identify.
Corpus Assembly
Any digital project needs to begin with the assembly of a machine-readable corpus. My corpus consisted of three digitised texts, each between 400 and 600 pages in length, sourced from the Bibliothèque nationale de France, with complete and high-quality scans available online through Gallica. All three texts are different recollections of the final campaign against Mahmadou Lamine Dramé, written by prominent French officers and colonial administrators.
Preparing the corpus for digital analysis involved, first, acquiring usable text files. Next, the data had to be “cleaned” of elements deemed obstructive to analysis, leaving a manipulable mass of tokens. Because my project focuses on semantics, elements such as page numbers had to be ignored by the pipeline, as did punctuation (except when used for sentence segmentation) and extraneous whitespace.
Language Challenges and Preprocessing
The French language, which is the language of all the texts, also presents specific challenges for cleaning. These were addressed through normalization, stop-word lists, and lemmatisation:
- Normalization: instructs the pipeline to ignore diacritics, dashes, and other orthographic elements (implemented via
re.sub). -
Stop words: deciding on stop words was perhaps the most important step, as this choice depends heavily on the type of analysis being performed. French contains many highly frequent short words—prepositions, articles, and clitics—which, in frequency-based analysis, can introduce “noise” and obscure meaningful results. One example of this phase going wrong is this:

- Lemmatisation: essential in languages with many inflected forms, where variants across tenses can appear as distinct words (for example, avoir → avait and être → était). Lemmatisation “collapses” these variants into a single base form, improving analytical clarity.
While condensing the number of words and focusing on longer, more distinctive lexical items is one viable approach, fully excluding smaller functional words can become an analytical pitfall in sentence-level analysis. Such words can significantly alter meaning when attached to larger expressions. This consideration motivated my use of a TF-IDF model to automatically identify bigrams and trigrams—combined expressions treated as distinct values in my word clouds. For example, expressions such as “nos relations” emerged as meaningful units.

Initial Analysis and Pipeline Development
In the early stages of the project, I developed a script that operated on relatively large textual chunks, allowing me to test whether basic frequency-based methods could surface meaningful patterns in the corpus. At this stage, a major focus was the construction of a cleaned and curated list of French stop words, as highly frequent words were obscuring more semantically relevant terms.
As the analysis progressed, I reduced chunk size to increase semantic precision and began experimenting with clustering approaches. I ultimately chose a combined TF-IDF and K-Means pipeline, which allowed textual units to be vectorised and grouped based on shared vocabulary.
My inspiration for the latter phases of the project came primarily from the article Text Mining Tafsir: Compilation and Preliminary Explorations of a Curated Corpus of 80 Qurʾanic Commentaries by Jurczyk et al. In this article, the authors performed initial surveys addressing semantic questions in order to demonstrate the viability of various digital models for semantic analysis. While their corpus was larger and more complex than mine, they employed general, largely reproducible methods. Following their approach, I adopted elements of their process, including a sliding-window method, word-cloud construction, and embedding. However, unlike the authors—who primarily used BERTopic—I relied on TF-IDF for vectorisation (thereby completing the embedding step and making cleaned tokens available for clustering) and for word-cloud construction, and opted for K-Means to perform topic modelling and clustering.
Cluster Labeling and Sentence-Level Refinement
The first series of clusters proved difficult to interpret, as they lacked inherent labels. To address this, I implemented automatic cluster labelling using TF-IDF feature weights. Even with these improvements, early results remained unsatisfactory: clusters were still dominated by short words and highly frequent verb forms such as avoir. Additionally, stop words applied during early stages were inadvertently reintroduced during clustering in initial versions of the code. I therefore introduced stricter token-length thresholds and lemmatisation to collapse variants into base forms.

Following this, I reoriented the analysis around sentence-level units rather than chunks, reasoning that sentences offered a more meaningful scale for capturing discourse and attribution. I also implemented a soft-filtering ruleset to group references to Mahmadou (e.g., Mahmadou, Laminé, and the shorthand “le marabout”) in order to focus more closely on my primary actors. This shift required further cleaning and lemmatisation procedures, after which I explored the use of bigrams and trigrams through TF-IDF vectorisation to capture recurring multi-word expressions. This also enabled the construction of contrastive word clouds, which highlight terms statistically distinctive to particular clusters, rather than those which appear the most in a corpus. Both standard frequency-based and contrastive word clouds are presented to demonstrate the difference in interpretive value.
Code Structure
At this stage, the codebase had a tripartite structure:
- Normalize the data and generate the CSV.
- Import K-Means and assemble clusters.
- Use TF-IDF to automatically label clusters.
At times, I also experimented with a fourth script examining distributions.
Findings
I was particularly interested in the word clouds for clusters 0 and 1.
- Cluster 0: notions of total war without negotiation are associated with references to Mahmadou and his various names.
- Cluster 2: conciliatory and diplomatic—though still militarised—relations are associated with Mahmadou’s regional rival and France’s temporary strategic partner, the “Sultan” Ahmadou.
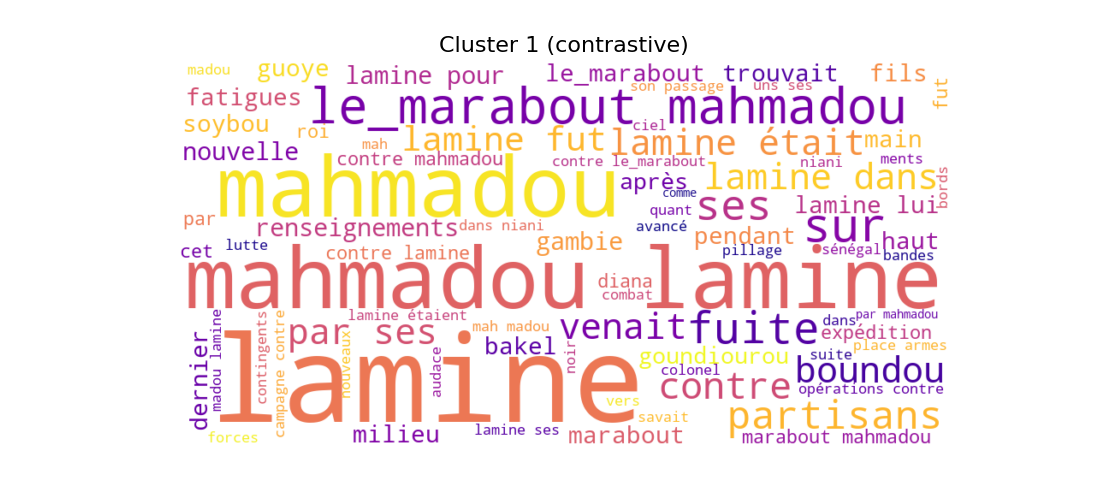
These patterns offer coherent interpretive avenues relevant to my thesis concerning the distinct semantic spaces occupied by Mahmadou and Ahmadou in French colonial writings of the period.
Reflections and Limitations
This project demonstrated that producing code for semantic analysis can be an arduous process. Filtering out data that was removed and later reintroduced at different stages of the pipeline proved to be a recurring challenge. Nevertheless, the project also showed that cluster-based analysis can be particularly fruitful, even for smaller-scale corpora, and can open up new avenues for historical and textual exploration.
It is worth noting what this project does not attempt. While clustering was central to the analysis, I did not pursue alternative visualisations such as two-dimensional embedding plots (e.g., PCA or t-SNE), instead prioritising textual interpretability over spatial representation. A matrix-based distribution would also be useful for more fully understanding the data, and I hope to develop such models in future work to refine and extend the present results. Nonetheless, the word clouds alone already provoke meaningful reflections on the texts and their semantics.